Abstract
Large vision-language models have driven remarkable progress in open-vocabulary robot policies, e.g., generalist robot manipulation policies, that enable robots to complete complex tasks specified in natural language. Despite these successes, open-vocabulary autonomous drone navigation remains an unsolved challenge due to the scarcity of large-scale demonstrations, real-time control demands of drones for stabilization, and lack of reliable external pose estimation modules. In this work, we present SINGER for language-guided autonomous drone navigation in the open world using only onboard sensing and compute. To train robust, open-vocabulary navigation policies, SINGER leverages three central components: (i) a photorealistic language-embedded flight simulator with minimal sim-to-real gap using Gaussian Splatting for efficient data generation, (ii) an RRT-inspired multi-trajectory generation expert for collision-free navigation demonstrations, and these are used to train (iii) a lightweight end-to-end visuomotor policy for real-time closed-loop control. Through extensive hardware flight experiments, we demonstrate superior zero-shot sim-to-real transfer of our policy to unseen environments and unseen language-conditioned goal objects. When trained on ~700k-1M observation action pairs of language conditioned visuomotor data and deployed on hardware, SINGER outperforms a velocity-controlled semantic guidance baseline by reaching the query 23.33% more on average, and maintains the query in the field of view 16.67% more on average, with 10% fewer collisions.
Data Synthesis
(1) We use language embedded 3D Gaussian Splatting to create training data from arbitrary objects. Rapidly exploring Random Trees (RRT*) are used to generate trajectories through the environment.
(2) We use a simulated robust model predictive control expert policy to track these trajectories, storing the control actions as training data. As we do this, we render ego-view camera images in the Gaussian Splat, and process them with a dense semantic segmentation image processor to create language conditioned visuomotor training data.
Network Architecture
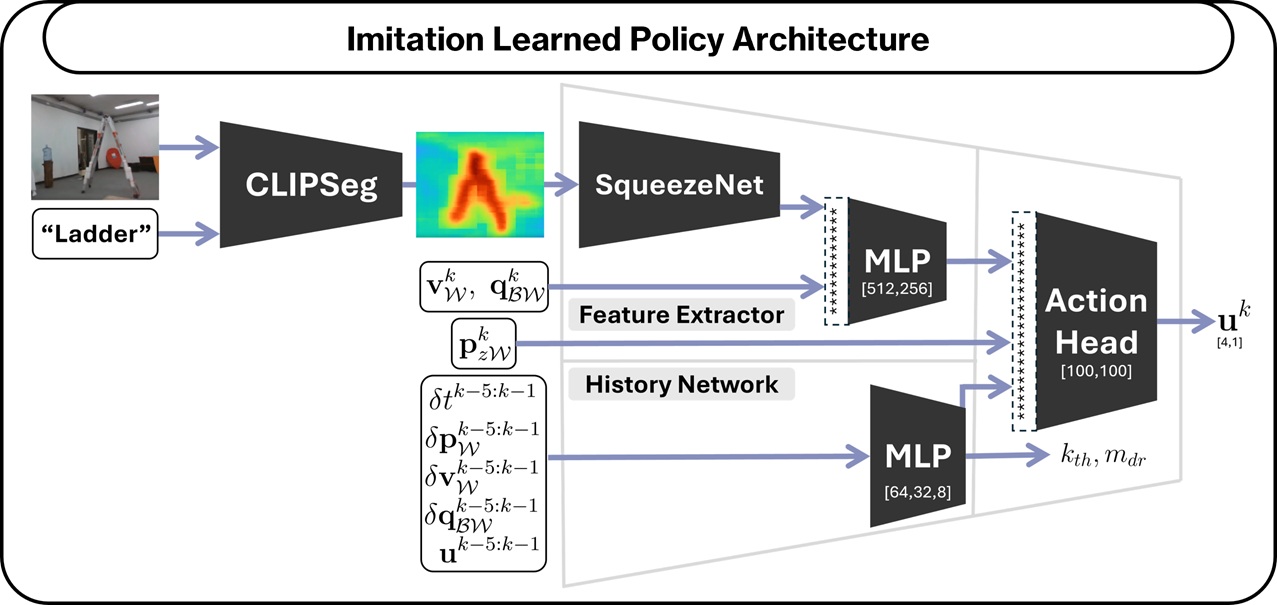
SINGER uses a lightweight end-to-end visuomotor policy trained via imitation learning from an expert model predictive controller. The policy takes as input an ego-view RGB image and a natural language query specifying the goal object, and directly outputs real-time control actions for closed-loop drone navigation. This architecture enables onboard inference with minimal latency, allowing the drone to reactively navigate toward open-vocabulary targets using only onboard sensing and compute.
Experiments
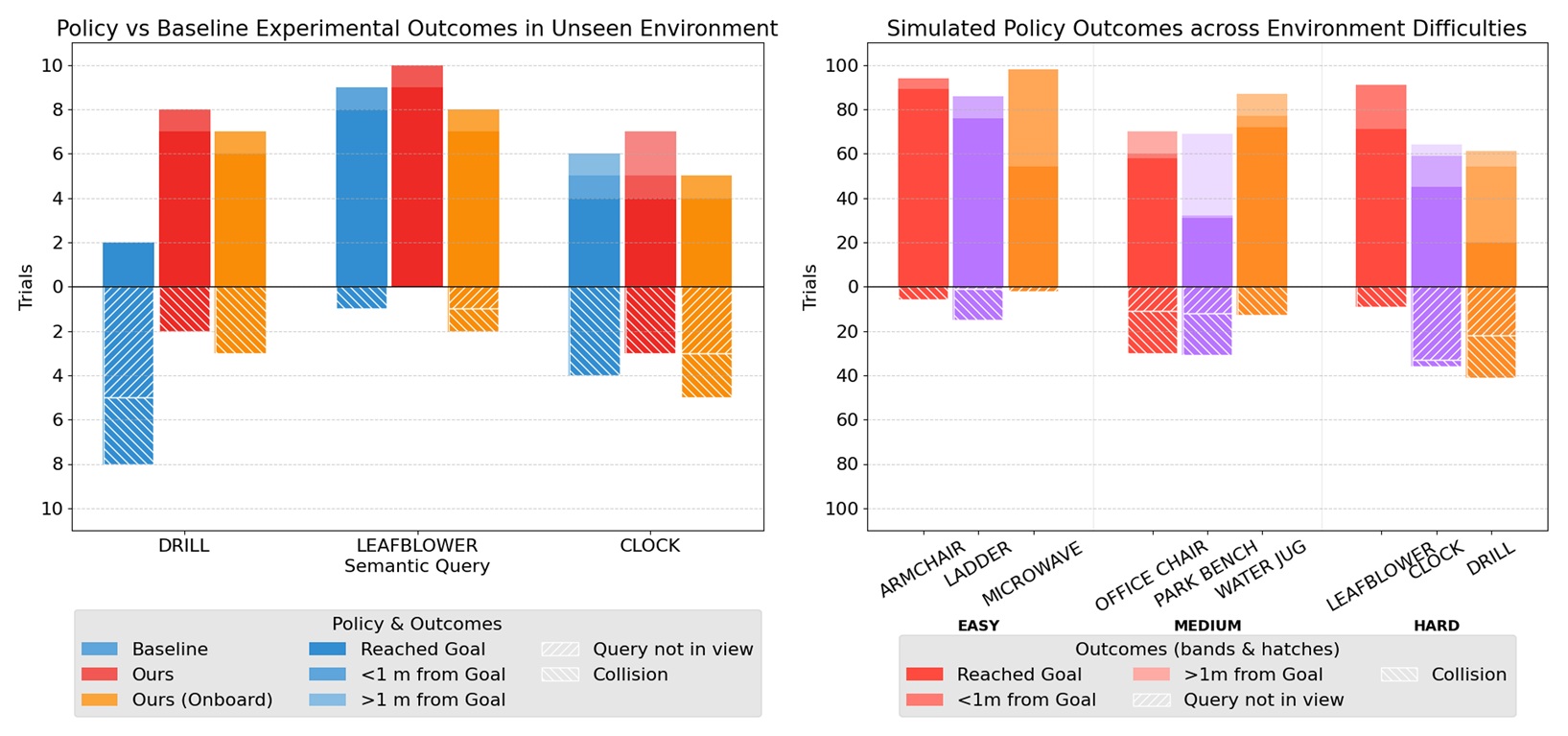
We compare SINGER against a velocity-controlled semantic guidance baseline that decouples perception and control—using a vision-language model to identify targets and a separate velocity controller for navigation. In contrast, SINGER's end-to-end visuomotor policy directly maps RGB images and language queries to control actions. We evaluate two SINGER variants: one using motion capture for ground-truth orientation, and another relying solely on the drone's internal compass, which is subject to sensor noise. This comparison demonstrates the policy's robustness to realistic onboard sensing conditions.
BibTeX
@misc{adang2025singeronboardgeneralistvisionlanguage,
title={SINGER: An Onboard Generalist Vision-Language Navigation Policy for Drones},
author={Maximilian Adang and JunEn Low and Ola Shorinwa and Mac Schwager},
year={2025},
eprint={2509.18610},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2509.18610},
}